Building a RAG system with Meilisearch: a comprehensive guide
Discover best practices for building a RAG system, with tips on optimizing documents, integrating AI, and why effective retrieval is key to success.

In this article
Building a retrieval-augmented generation (RAG) system allows you to connect large language models (LLMs) to real-time data, helping them return accurate answers rather than generic responses.
Understanding how RAG works is particularly useful when creating a customer support bot or a research tool:
- The RAG system converts the user question into vector embeddings and searches an external database for any relevant information on the topic. It then feeds the retrieved data to an AI that generates accurate, grounded responses.
- RAG connects AI to external data sources and provides verifiable answers that you can trace back to the relevant documents.
- Common challenges that you are likely to face when building a RAG system include messy data, accuracy issues with retrieval, and balancing chunk sizes. You may also face latency issues and AI hallucinations despite using external material.
- Advanced RAG approaches, such as GraphRAG, modular RAG, and corrective RAG, tackle specific use cases beyond basic retrieve-and-generate patterns.
What is a RAG system?
RAG is a process that enhances LLM outputs by grounding them in external, retrievable data. Instead of relying solely on the model's trained knowledge, RAG systems first retrieve relevant information from a curated knowledge base, then use this context to generate responses.
The typical RAG workflow consists of three main steps:
- Retrieval: The knowledge base is queried to find relevant documents or passages.
- Augmentation: The retrieved information is combined with the user's query.
- Generation: The LLM generates a response based on both the query and the retrieved context.
How does a RAG system work?
A RAG system uses relevant information from an external source to enhance the quality of AI responses.
Here is how it works:
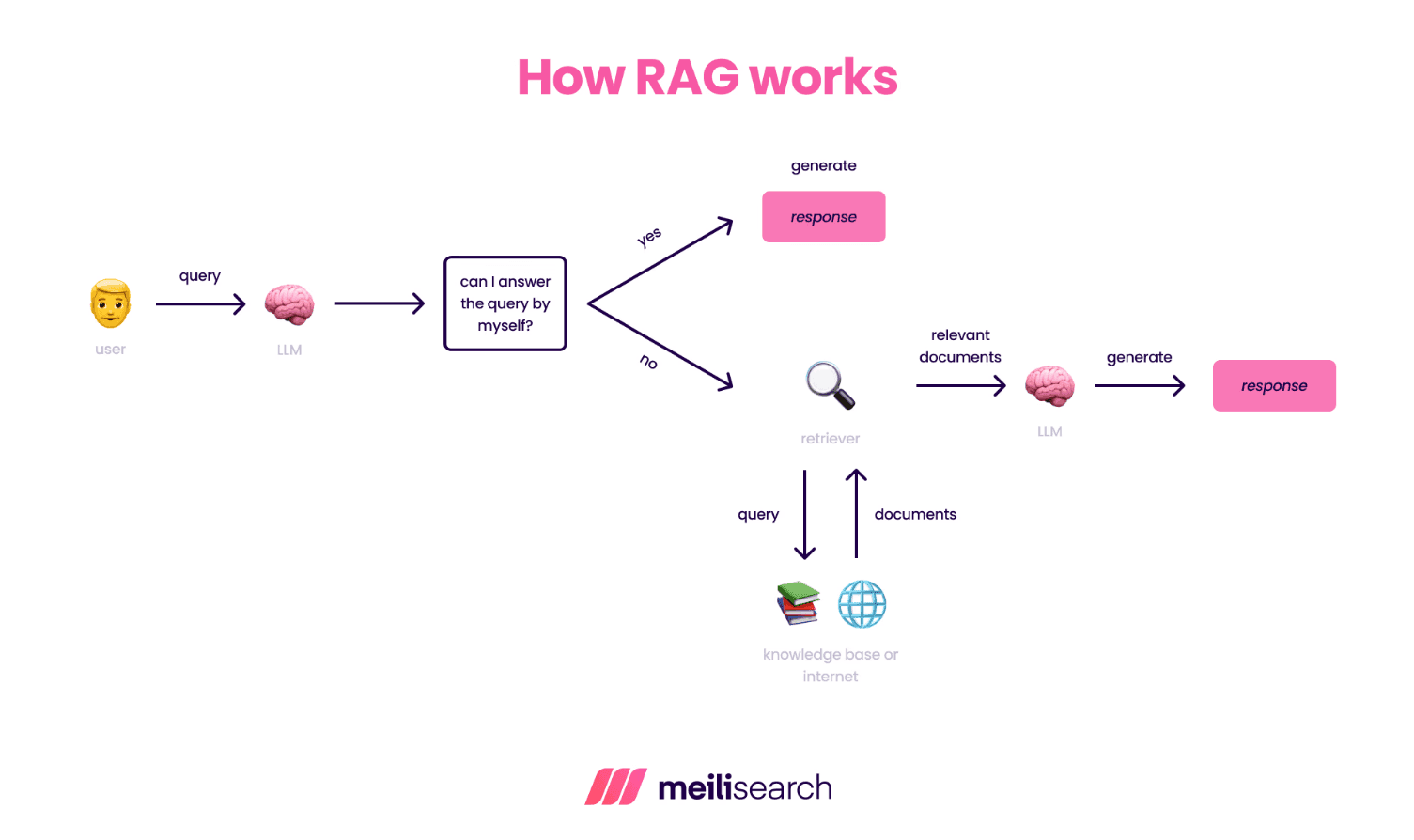
When a user asks a question, the system first converts the text into a numerical representation – a vector embedding. It then searches through a database of pre-processed documents, also stored as embeddings, to find the most relevant information as chunks.
Once RAG retrieves these relevant chunks, it feeds them to the language model along with the original user question. The LLM then crafts a response based on both the query and the retrieved information.
This provides the user with accurate answers based on real data.
What are the main components of a RAG system?
A RAG system comprises three essential components:
- External data source: External data sources are the foundation of a RAG system. These sources, such as knowledge bases or technical documentation, provide the information the LLM uses to generate responses. The quality of this data directly impacts performance; it must be well-organized and regularly updated to ensure accuracy and relevance.
- Vector store: The vector store serves as the bridge between raw data and the LLM. It converts text into vector embeddings (numerical representations of meaning). These vectors enable efficient similarity searches, allowing for the quick retrieval of relevant information. Tools such as Meilisearch combine keyword search with semantic similarity to deliver fast, scalable results.
- Large language model: The LLM is the system's intelligence, responsible for understanding user queries and generating coherent, relevant responses. It combines user queries with context retrieved from the vector store to produce accurate replies. Models like GPT-4, Claude, or Llama 2 excel at creating human-like responses within the constraints of the provided context.
Let’s look at the main reasons why we build RAG systems.
Why build a RAG system?
Traditional AI systems without RAG are limited to the information available in their training data. This can lead to the system's knowledge base becoming outdated.
For instance, if you want an AI to answer about a company's recent events, a basic model will either hallucinate or admit it doesn’t know.
RAG systems address this issue by enabling an AI system to return more relevant answers without retraining the models. With RAG, you can connect the AI to real data sources. By pulling real information from these sources, responses become more up-to-date and accurate.
You can also trace answers back to specific documents.
In addition, RAG systems are not difficult to update – you simply add new documents to the database. This is faster and more cost-effective than retraining the model from scratch.
Typical uses for RAG systems include customer support bots that reference help documents within an organization and legal research tools that find related materials to enhance an attorney’s case.
Why LLMs need RAG: overcoming key limitations
Large language models excel at general knowledge but face two significant limitations:
- They struggle with specialized domain-specific information.
- They are constrained by their latest training sessions, relying on outdated knowledge and often lagging months or even years behind current advancements.
RAG lets you tackle both challenges at once. For instance, a legal firm can enhance its LLM's capabilities by incorporating not only its historical case archives but also the latest court decisions and regulatory changes. A healthcare provider may integrate established medical literature, recent clinical trials, and updated treatment protocols.
The ability to continuously update your knowledge base ensures that your LLM-powered applications can provide accurate, up-to-date responses that combine deep domain expertise with the latest information in your field.
How to optimize document retrieval in RAG systems
Efficient information retrieval is crucial for RAG. Without precise and relevant document retrieval, even the most advanced LLMs can produce inaccurate or incomplete responses.
Choosing the right document retrieval system is a crucial step in this process.
Meilisearch offers a fast, open-source search engine that supports keyword searches and more advanced AI-powered search approaches that combine exact word matching with semantic search. This dual capability makes it an ideal tool for RAG systems, where the goal is to retrieve not only documents that match keywords but also those that are semantically related.
Meilisearch offers a range of features suited explicitly for RAG systems:
- Easy embedder integration: Meilisearch automatically generates vector embeddings, enabling high-quality semantic retrieval with minimal setup and flexibility to choose the latest embedder models.
- Hybrid search capabilities: Combine keyword and semantic (vector-based) search to deliver broader, more accurate document retrieval.
- Speed and performance: Meilisearch delivers ultra-fast response times, ensuring retrieval never becomes a bottleneck in your LLM workflow.
- Customizable relevancy: Adjust ranking rules and sort documents based on attributes such as freshness to prioritize the most valuable results. Set a relevancy threshold to exclude less relevant results from the search.
Once you have established your retrieval system, the next step is to optimize how your data is stored, indexed, and retrieved. The following strategies (document chunking, metadata enrichment, and relevancy tuning) will ensure that every search query returns the most useful and contextually relevant information.
How to chunk documents to maximize relevancy
Breaking down documents into optimal-sized chunks is crucial for effective retrieval. Chunks should be large enough to maintain context but small enough to be specific and relevant. Consider semantic boundaries, such as paragraphs or sections, rather than arbitrary character counts.
Enriching metadata to boost search precision
Enhance your documents with rich metadata to improve retrieval accuracy. Include categories, tags, timestamps, authors, and other relevant attributes.
For example, tagging technical documentation with specific product versions can significantly improve retrieval quality.
Adjusting relevancy for accurate results
Fine-tune your search parameters based on your specific use case. Adjust the hybrid search semantic ratio to balance conceptual understanding and exact matching based on your domain's needs. Use the ranking score threshold to filter out low-quality matches, but be careful not to set it too high and miss valuable contextual information.
Setting up Meilisearch for RAG
The quality of the retrieval system directly impacts the accuracy and reliability of generated responses.
Meilisearch stands out as a search engine for RAG implementations, thanks to its AI-powered search capabilities, customizable document processing, and advanced ranking controls.
Set Meilisearch up
Unlike traditional vector stores that rely solely on semantic search, Meilisearch combines vector similarity with full-text search, giving you the best of both worlds.
First, you need to create a Meilisearch project and activate the AI-powered search feature.
Then, you need to configure the embedder of your choice. We are going to use an OpenAI embedder, but Meilisearch also supports embedders from HuggingFace, Ollama, and any embedder accessible via a RESTful API:
import os import meilisearch client = meilisearch.Client(os.getenv('MEILI_HOST'), os.getenv('MEILI_API_KEY')) # An index is where the documents are stored. index = client.index('domain-data') index.update_embedders({ "openai": { "source": "openAi", "apiKey": "OPEN_AI_API_KEY", "model": "text-embedding-3-small", "documentTemplate": "A document titled '{{doc.hierarchy_lvl1}}'. Under the section '{{doc.hierarchy_lvl2}}'. This is further divided into '{{doc.hierarchy_lvl3}}'. It discusses {{doc.content}}." } })
Note: You'll need to replace OPEN_AI_API_KEY with your OpenAI API key.
Smart document processing with Meilisearch's document template
Meilisearch’s document template allows you to customize embeddings for each document, ensuring only the most relevant fields are included.
Customizing your document processing helps you:
- Increase retrieval relevance with precise embeddings
- Lower costs by reducing unnecessary tokens
- Ensure consistency across different document types
- Support domain-specific needs for unique data formats
- Iterate and refine embedding strategies as your system evolves
Here’s an example document from the Meilisearch documentation:
{ "hierarchy_lvl1":"Filter expression reference" "hierarchy_lvl2":"Filter expressions" "hierarchy_lvl3":"Creating filter expressions with arrays" "content":"Inner array elements are connected by an OR operator. The following expression returns either horror or comedy films" "hierarchy_lvl0":"Filtering and sorting" "anchor":"creating-filter-expressions-with-arrays" "url":"https://www.meilisearch.com/docs/learn/filtering_and_sorting/filter_expression_reference#creating-filter-expressions-with-arrays" "objectID":"bbcce6ab00badb2a377b455ba16180d" "publication_date":"1733986800" }
To optimize the embeddings for this document, we’ve decided to focus on the most meaningful fields:
- Headings: The values of hierarchy_lvl0 to hierarchy_lvl3 will be included in the embeddings to retain document structure and context
- Content: The value of content will be embedded as it provides the essential text needed for semantic search
Other fields, like publication_date, will be excluded from embeddings but remain available for sorting. This allows Meilisearch to sort by date while keeping embeddings lean and focused on relevancy
Meilisearch customizable ranking rules
Meilisearch offers fine-grained control over result ranking, enabling you to customize how search results are ordered and prioritized. This control ensures that users see the most relevant content first, tailored to your specific business or domain needs.
Unlike fixed ranking systems, Meilisearch allows you to define your own ranking rules. This flexibility helps you prioritize certain types of content, promote newer or more relevant results, and create a search experience that aligns with user expectations.
For instance, we have added to the default ranking rules, a custom rule that promote newer documents.
# Configure settings import os import meilisearch # Initialize the Meilisearch client client = meilisearch.Client(os.getenv('MEILI_HOST'), os.getenv('MEILI_API_KEY')) # An index is where the documents are stored. index = client.index('domain-data') index.update_settings({ 'rankingRules': [ "words", "typo", "proximity", "attribute", "sort", "exactness", "publication_date:desc", ], 'searchableAttributes': [ 'hierarchy_lvl1', 'hierarchy_lvl2', 'hierarchy_lvl3', 'content' ] })
Index your documents
After setting up Meilisearch and preparing your data using best practices like document chunking and metadata enrichment, you can now push your data to Meilisearch.
Meilisearch accepts data in .json, .ndjson, and .csv formats. There are several ways to upload your documents:
- Drag and drop files into the Cloud UI.
- Use the API via the
/indexes/{index_uid}/documentsroute. - Call the method from your preferred SDK
💡 Note: Your documents must have a unique identifier (id). This is crucial for Meilisearch to identify and update records correctly.
Here’s how to upload documents using the Python SDK:
import os import meilisearch import json # Initialize Meilisearch client client = meilisearch.Client(os.getenv('MEILI_HOST'), os.getenv('MEILI_API_KEY'))) # Select or create the index index = client.index('domain-data') # Load the JSON file with open('path/to/your/file.json', 'r') as file: documents = json.load(file) # Load the array of JSON objects as a Python list # Add documents to Meilisearch index.add_documents(documents)
Perform an AI-powered search
Perform AI-powered searches with q and hybrid to retrieve search results using the embedder you configured earlier.
Meilisearch will return a mix of semantic and full-text matches, prioritizing results that match the query's meaning and context. You can fine-tune this balance using the semanticRatio parameter:
index.search( userQuery, { "hybrid": { "embedder": "openai", "semanticRatio": 0.7 # 70% semantic, 30% full-text } } )
This flexible control lets you:
- Optimize the balance to fit your specific use case.
- Adapt in real-time based on query patterns.
- Combine the strengths of both methods, ensuring you don't miss key results.
This dual approach ensures you won't miss relevant results that might slip through the cracks of pure semantic search, while maintaining the benefits of semantic understanding.
Quality control with ranking score threshold
The rankingScoreThreshold parameter ensures that only high-quality results are included in the search response. It works in tandem with the ranking score, a numeric value ranging from 0.0 (poor match) to 1.0 (perfect match). Any result with a ranking score below the specified rankingScoreThreshold is excluded.
By setting a ranking score threshold, you can:
- Filter out low-relevance results to improve overall result quality
- Provide better context for RAG systems, ensuring LLMs work with higher-quality data
- Reduce noise in search results, minimizing irrelevant information
- Customize relevancy to align with your specific use case needs
The following query only returns results with a ranking score bigger than 0.3:
index.search( userQuery, { "hybrid": { "embedder": "openai", "semanticRatio": 0.7 # 70% semantic, 30% full-text }, "rankingScoreThreshold": 0.4 } )
Ready to build your RAG system? Now that we've set up Meilisearch. We'll walk you through the steps to create a RAG system with Meilisearch.
Implementing RAG with Meilisearch
We'll build a RAG system using the Meilisearch documentation as our example knowledge base, demonstrating how to retrieve, process, and generate accurate, context-aware responses.
Key technologies used
Our implementation leverages several key technologies:
- FastAPI: powers the API that handles user queries
- Meilisearch: retrieves the relevant content
- OpenAI's GPT-4: generates human-like, contextual responses
- LangChain: orchestrates the AI workflow by chaining the search and LLM response generation.
How the system works
When a user submits a question, the system follows these steps:
- User input: The user submits a query to the API
- Content retrieval: Meilisearch searches for the most relevant content using a combination of keyword and semantic search
- Context construction: the system builds a hierarchical context from the search results
- LLM generation: the context and user query are sent to GPT-4 to generate an accurate, practical response
- Response delivery: the system returns the LLM-generated answer along with the sources used to generate it
Setting up the environment
API keys and credentials are stored on environment variables in a .env file. We use dotenv to load them.
Here's how key services are initialized:
- Meilisearch client: connects to the Meilisearch instance using the host and API key.
- OpenAI client: authenticates the GPT-4 LLM via an API key
- FastAPI application: sets up the web API for users to interact with the system
import os
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from meilisearch import Client
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize FastAPI application
app = FastAPI()
# Initialize Meilisearch client
client = meilisearch.Client(os.getenv('MEILI_HOST'), os.getenv('MEILI_API_KEY')))
# Initialize OpenAI
llm = ChatOpenAI(temperature=0, model="gpt-4o", api_key=os.getenv('OPENAI_API_KEY'))
Configuring CORS middleware
To ensure the system can handle requests from different origins (like frontend clients), we configure Cross-Origin Resource Sharing (CORS) for the FastAPI app. This allows cross-origin requests from any domain.
# Configure CORS middleware to allow cross-origin requests
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # Allows all origins
allow_credentials=True, # Allows credentials (cookies, authorization headers, etc.)
allow_methods=["*"], # Allows all HTTP methods
allow_headers=["*"], # Allows all headers
)
Defining the Query Data Model
The Query class defines the data structure for incoming POST requests. This ensures that only queries with a valid question are accepted.
class Query(BaseModel):
question: str
How it works:
- Input validation: FastAPI will automatically validate that incoming
POSTrequests contain a valid question field of type string - Data parsing: The incoming query is parsed into a
Queryobject that can be used inside the endpoint
Defining the API endpoint
The API exposes a single POST endpoint (/query) where users send a query. This endpoint retrieves relevant content, constructs a context, and returns an answer from GPT-4.
@app.post("/query")
async def query_documents(query: Query):
"""Query documents and generate response using RAG."""
Querying Meilisearch for relevant documents
The system queries Meilisearch using a hybrid search approach that combines semantic search (70%) with keyword search (30%). It also enforces a rankingScoreThreshold of 0.4, ensuring only high-quality results are included.
try:
# Prepare search parameters
search_params = {
"hybrid": {
"embedder": "openai",
"semanticRatio": 0.7 # 70% semantic, 30% full-text
},
"limit": 5, # restricts results to 5 documents
"rankingScoreThreshold": 0.4
}
# Search Meilisearch
search_results = meili.index('domain-data').search(
query.question,
search_params
)
Constructing the context for GPT-4
Once Meilisearch returns the search results, the system processes them to create a structured context. The context preserves the hierarchical structure of the documents, ensuring that headings and subheadings are retained.
Context construction process
- Extract Hierarchical Data: the system pulls hierarchical levels (hierarchy_lvl0, hierarchy_lvl1, etc.) from the search results.
- Concatenate context: the headings and main content are combined to create a clear, readable context.
- Separate Sections: each document's context is separated using "---" to improve clarity for GPT-4.
# Prepare context from search results
contexts = []
for hit in search_results['hits']:
context_parts = []
# Add hierarchical path
for i in range(4): # levels 0-3
hierarchy_key = f'hierarchy_lvl{i}'
if hit.get(hierarchy_key):
context_parts.append(f"{' ' * i}> {hit[hierarchy_key]}")
# Add content
if hit.get('content'):
context_parts.append(f"\nContent: {hit['content']}")
contexts.append("\n".join(context_parts))
context = "\n\n---\n\n".join(contexts)
Generating a response with GPT-4
The assembled context is passed to GPT-4 along with the user's question. A precise prompt ensures responses are:
- practical and implementation-focused
- based on actual documentation
- clear about limitations when information isn't available
# Create prompt template
prompt_template = """You are a helpful Meilisearch documentation assistant. Use the following Meilisearch documentation to answer the question.
If you cannot find the answer in the context, say so politely and suggest checking Meilisearch's documentation directly.
Provide practical, implementation-focused answers when possible.
Context:
{context}
Question: {question}
Answer (be concise and focus on practical information):"""
Running the LLMChain with LangChain
- Create LLMChain: this links GPT-4 to the formatted prompt.
- Send input: the user query and context are sent to the LLM for processing.
- Return response: the LLM's response is returned to the user.
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# Create and run chain
chain = LLMChain(llm=llm, prompt=prompt)
response = chain.run(context=context, question=query.question)
Assembling the final API response
The final API response includes:
- LLM-generated answer
- Sources (URLs and hierarchy of the documents used)
return {
"answer": response,
"sources": [{
'url': doc.get('url', ''),
'hierarchy': [
doc.get(f'hierarchy_lvl{i}', '')
for i in range(4)
if doc.get(f'hierarchy_lvl{i}')
]
} for doc in search_results['hits']]
}
Handling errors and exceptions
To avoid system crashes, all exceptions are caught and returned as an error response.
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Running the application
Finally, you can run the API locally using Uvicorn. This command starts the FastAPI app on localhost:8000.
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
At this point, your RAG system is live, able to retrieve relevant context and generate precise answers using Meilisearch and GPT-4.
How to evaluate the performance of your RAG system
After building your RAG system, you need to verify that it functions as intended. Here are some things you should follow up on:
Ensuring high-quality content in RAG systems
Maintain high standards for your document base. Regularly audit and update your content to ensure accuracy and relevance. Remove duplicate or outdated information that might dilute search results.
Establish a process for validating and updating information to maintain the integrity of the knowledge base.
Monitoring performance to identify bottlenecks
Implement monitoring to track retrieval effectiveness. Watch for patterns in failed queries or consistently low-ranking results. Use this data to refine your document processing and search parameters.
Monitor both technical metrics (such as response times) and quality metrics (such as relevance scores) to ensure optimal performance. This can be easily done through the Meilisearch Cloud monitoring metrics and analytics dashboards.
Collecting user feedback
User feedback is one of the most valuable sources for improving the performance of your RAG system. While metrics such as query latency or relevance scores provide technical insights, user feedback reveals real-world problems.
By collecting and analyzing feedback, you can identify issues that are harder to detect with system metrics alone, such as:
- False positives: When irrelevant results are returned for a query.
- Missed context: When the system fails to retrieve a document that users expected to see.
- Slow responses: When users experience slow loading times or incomplete responses.
User feedback can guide you in fine-tuning your Meilisearch configuration. It might highlight the need to adjust sorting to prioritize more recent documents, raise the rankingScoreThreshold to filter out low-relevance results, optimize the documentTemplate to embed more relevant context, or chunk large documents into smaller, more targeted sections to improve retrieval accuracy.
Let’s see the challenges that you could face when building your RAG systems.
What are common challenges when building a RAG system?
Building a RAG system comes with several practical challenges that you will need to address. The most significant include:
- Data quality and preparation: Your source documents need proper cleaning and chunking. If you do not correctly chunk, index, and embed the source documents, the system will retrieve irrelevant chunks and produce bad answers.
- Retrieval accuracy: Sometimes the search engines miss the correct information entirely. Getting the embedding model and search parameters tuned correctly takes experimentation, time, and practice.
- Chunk size tradeoffs: Small chunks might miss context, while large chunks can dilute the relevant bits with noise. Finding the sweet spot depends on your specific context and may require testing.
- Latency issues: Each query requires both a database search and an AI generation. This adds extra time to the response time. From an end-user perspective, the waiting time can be dissatisfying. Unfortunately, optimizing latency issues without sacrificing quality can be challenging.
- Context window limitations: You can only feed so much retrieved text to the language model before hitting token limits. You have to prioritize what to include in your context window.
- Hallucination despite grounding: Even with retrieved documents, the AI may still occasionally fabricate information or misinterpret the source material. It is essential to prepare for such risks by informing the user up front and having a human evaluate the system’s responses to provide feedback.
What are the best practices for scaling a RAG system?
Scaling a RAG system from prototype to production requires thinking through several infrastructure components.
Here are the recommended best practices you can follow:
- Vector database optimization: As your document collection grows, you will need a proper vector database (such as Pinecone, Weaviate, or Qdrant). These handle efficient indexing and approximate nearest-neighbor search. You may also consider sharding for high query volumes.
- Caching strategies: Implement smart caching at multiple levels. For instance, you should cache common queries, frequently accessed document chunks, and embeddings. This reduces latency and computational costs for repetitive questions.
- Model serving infrastructure: Use dedicated model serving platforms to handle traffic spikes. Consider implementing a load balancer across multiple model instances to prevent bottlenecks. Smaller models may be faster at generating responses. If they are sufficient for your use case, use smaller models for embedding and generation.
- Distributed retrieval: Split your document corpus across multiple servers or regions. Parallel retrieval speeds things up, especially with large knowledge bases. Architect the system to handle concurrent searches without degrading performance.
- Monitoring: Do not forget to track retrieval quality metrics, response times, cache hit rates, and user satisfaction. Log which documents get retrieved for each query so you can debug poor results and identify gaps in your knowledge base.
- Cost management: Monitor API costs for embeddings and generation. Batch processing and smart caching help control expenses as usage scales up.
What are some different types of RAG?
RAG systems have evolved beyond the basic retrieve-and-generate pattern. Here are some different types of RAG that tackle specific challenges:
- GraphRAG: Maps relationships between entities and concepts in a knowledge graph. Instead of treating documents as isolated chunks, GraphRAG captures how information connects across your data. This makes it better for complex queries that require context and relationship understanding.
- Modular RAG: Modular RAG breaks the RAG pipeline into small, swappable components. You can customize features such as retrieval methods, reranking strategies, and generation approaches to suit your specific needs. You can also mix and match different techniques for different query types.
- Corrective RAG: Adds a verification layer that checks whether the retrieved documents answer the question. If they do not, the corrective RAG system triggers an alternative retrieval strategy to find better information before generating a response.
- Speculative RAG: Generates multiple answers in parallel using different retrieval strategies. It then selects or combines the best results. Speculative RAG improves accuracy but also requires more computational resources.
- Adaptive RAG: Adaptive RAG adapts its retrieval strategy based on the query complexity. Simple questions might skip retrieval entirely, while complex ones could trigger multi-step searches or external lookups.
What is the future of RAG systems?
RAG systems are becoming more autonomous and context-aware. We now have multimodal RAG workflows that handle images, videos, code, and text. They are useful for visual search and technical documentation where teams want to understand images or long documents as an expert would.
Agentic RAG is fast-growing, where systems can decide when to retrieve information or chain multiple searches together.
Real-time RAG is another exciting development. It integrates live data streams, ensuring that you have current answers without requiring manual updates.
We are also seeing better personalization, where systems remember user preferences.
The overarching goal is to create a RAG that feels less like querying a database and more like consulting a knowledgeable assistant who can naturally synthesize information.
Key takeaways: maximizing RAG performance with Meilisearch
To get the best results from your RAG implementation, focus on a few core areas. Start with solid data preparation, fine-tune your approach for your specific domain by adjusting ranking rules, relevance thresholds, and embedding strategies to optimize performance. Continue to evaluate performance using user feedback and system metrics, then iterate based on the insights gained.
Building a RAG system with Meilisearch gives you several practical advantages. It integrates smoothly with various data sources and language models, ensuring you are not locked into a single ecosystem.
The retrieval is fast and resource-efficient, which is crucial when handling real user traffic. By combining keyword and semantic search, you get more accurate results than with either approach on its own.

Why intent understanding is the hardest part of AI-powered search (and how to solve it)
The challenge isn't connecting to an LLM. It's figuring out what people actually mean.

Knowledge graph vs. vector database for RAG: which is best?
Learn the key differences between knowledge graphs and vector databases for RAG, when to use each, and how to combine them for optimal results.

Retrieval-Augmented Generation (RAG) for business: Full guide
Explore how RAG for business boosts AI accuracy and delivers smarter, context-driven insights.