From ranking to scoring
Our journey to add relevancy scores to search results in Meilisearch.

Welcome to the word buffet! Make your order, and we’ll serve you our 20 finest documents, the ones that match your query the best! Well, we say finest, but we won’t exactly tell you how well they match your query, we just promise you they’re the best we have. Unacceptable, you say? You’re the most renowned restaurant critic from the area, and you need to be able to make the difference between the perfect match and a word salad, you say? oh, that sounds like trouble indeed…

Meilisearch is an open-source search engine that aims at offering a lightning-fast, hyper-relevant search with little integration effort. It enables storing documents on disk in groups called indexes and searching those indexes to fetch the documents pertinent to each query. By the way, if you want to make your life easier and focus on the search experience you provide, we offer a Cloud solution that always benefits of our latest releases 😉
Until the recent [release of version 1.3](/blog/v1-3-release/ Meilisearch provided no way to know how well a document matched a particular search query. This article gives an insight into the journey that led us to add this feature.
Motivation
Providing relevancy scores for documents serves many highly-requested use cases:
- Adapting how the search results are presented, depending on the score of the documents. For example, developer bakerfugu has a calendar application and wants to use color differentiation to highlight the relevancy of meetings and events. However, the search results order doesn’t suffice because even the top result could vary in relevancy. Without a score, we only know that it is the best Meilisearch could find.
- Implementing aggregated search. Aggregated search is a way of displaying the results coming from searching multiple indexes as if the search had been performed against a single unified index. Real-world use cases were reported by users in various GitHub discussions.
- Implementing sharding. Sharding is similar to federated search, in that it combines the results of multiple search queries. Unlike federated search, sharding involves querying a partitioned index over multiple Meilisearch instances, rather than querying multiple indexes in the same instance. The data is expected to be more homogeneous, but the re-ranking must be possible after the queries are made, “offline” so to speak.
- Understanding relevancy. Meilisearch uses a set of predefined rules to rank documents. By producing a detailed score for every ranking rule, it is possible to get a finer understanding of how individual rules apply to a document for a specific query. This facilitates discovering the best settings to maximize relevancy in each use case.
We can see from these four use cases that the design space to implement the scoring feature is large. What properties should the solution(s) exhibit to best address all these use cases? Let’s have a look at them.
Target properties
From the different use cases, we can see multiple distinct cohorts of users and usage. We identified two axes along which several solutions could be provided:
- Aggregate score versus detailed scores. For the calendar use case, a single “aggregate” score per document suffices, while for understanding relevancy, a detailed score per ranking rule is needed. The ideal solution should provide both aggregate and detailed scores.
- Machine-readable versus human-readable. Most use cases require information that can be digested automatically by the integrations or the frontends. However, if we aim to make relevancy easier to understand, we need to provide human-readable information. As a result, the solution should strike the right balance between these two properties.
Additionally, to enable aggregated search and sharding, the scores must be independent of the documents contained in the searched indexes. Indeed, if adding a document to an index changes the score of the other documents, then comparing that score to another index that contains different documents is meaningless.
Lastly, we wanted the score system to be intuitive: Meilisearch should return documents in decreasing order of relevancy score, following the principle of least astonishment.
This last property, in particular, biased us towards a solution that would be based on the ranking already performed by Meilisearch, as a means of guaranteeing consistency between the ranking and the scoring.
In summary, addressing a wide array of use cases requires a scoring feature that not only provides both aggregate and detailed scores, but also caters to machine and human readability. It should also maintain score independence, regardless of the documents in the searched indexes, and align with the existing ranking system by Meilisearch. To understand how we can build this scoring system based on ranking, we first need to understand the ranking itself.
Recursive bucket sorting
This section covers how Meilisearch ranks documents in response to a search query. If you already know the recursive bucket sorting algorithm used by Meilisearch, feel free to skip this section. Additionally, as this section is laser-focused on the search algorithm, it doesn’t cover other pieces of the engine such as indexing. If you’re interested in knowing more about these, we covered them previously in a [dedicated article](/blog/how-full-text-search-engines-work/
At its core, Meilisearch uses an algorithm called “bucket sorting”. It sorts documents into different buckets based on a set of ranking rules. The first ranking rule applies to all documents, while each subsequent rule is only applied as a tiebreaker to sort documents considered equal within a bucket. The sorting finishes when all the “innermost” buckets contain a single document, or after applying the last ranking rule.
For example, the words ranking rule sorts documents depending on the number of query words found in the document. If multiple documents end up in the same bucket, another ranking rule like typo is used to differentiate them.
For the query “Badman dark knight returns”, the words ranking rule will sort the returned documents into 4 buckets, from documents that contain all the words (possibly with a typo) to documents that only contain “Badman”. The typo ranking rule helps us further differentiate between documents from the last bucket.
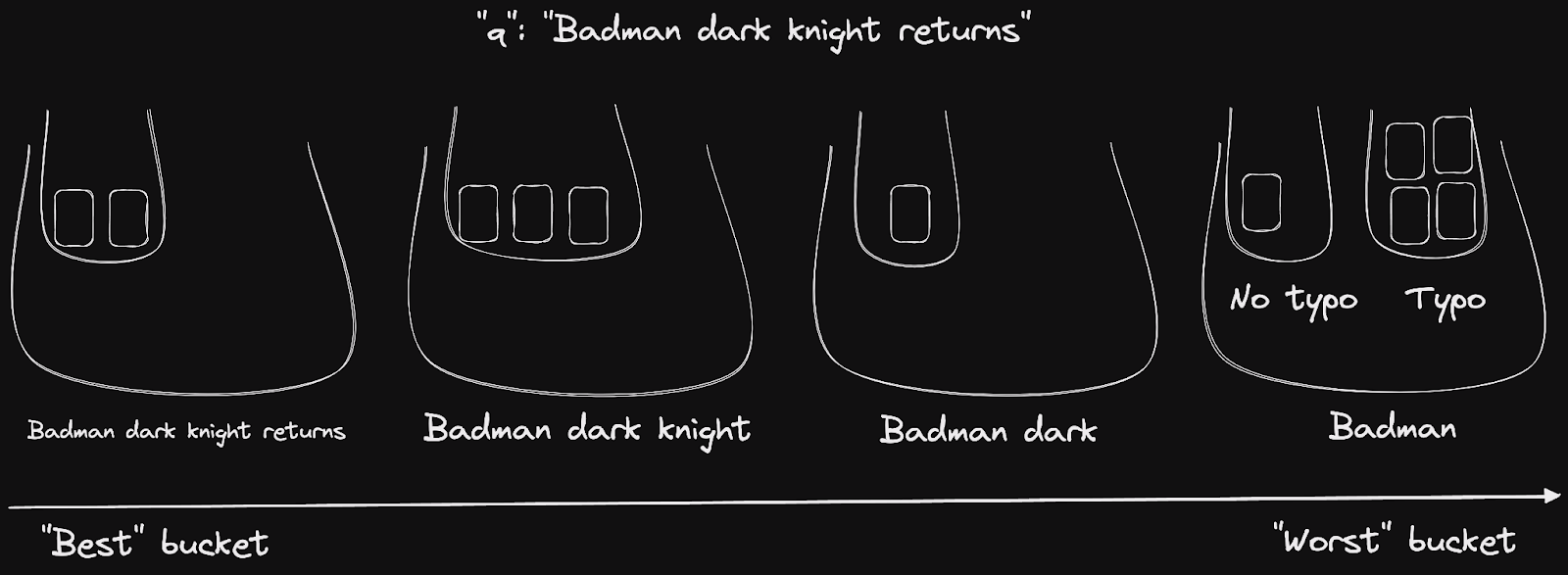
👉 Note that this rule has no effect on the three other buckets, because they only contain documents such that the query has the typo “Badman -> Batman”.
Now that we have a good understanding of the way Meilisearch ranks documents, let's recap our desired properties for the scoring feature:
- It should provide both aggregate and detailed scores
- It should cater to both machine and human readability
- It should maintain score independence, regardless of the documents in the searched indexes
- It should align with Meilisearch's existing ranking system.
How can we extend Meilisearch’s ranking behavior to generate scores that satisfy these criteria? We'll explore this next.
From sorting to scoring
Following what we just learned, each ranking rule splits the entire dataset into several buckets and then returns them in order. We can then use the rank of each bucket and the total number of buckets per rule to compute a score, giving rise to the recursive bucket scoring algorithm.

Let’s reuse our leading “badman” example to put that into practice. We count the number of words buckets to be 4, and for each of these buckets, the number of inner typo buckets. We arrive at what is presented in the diagram below.
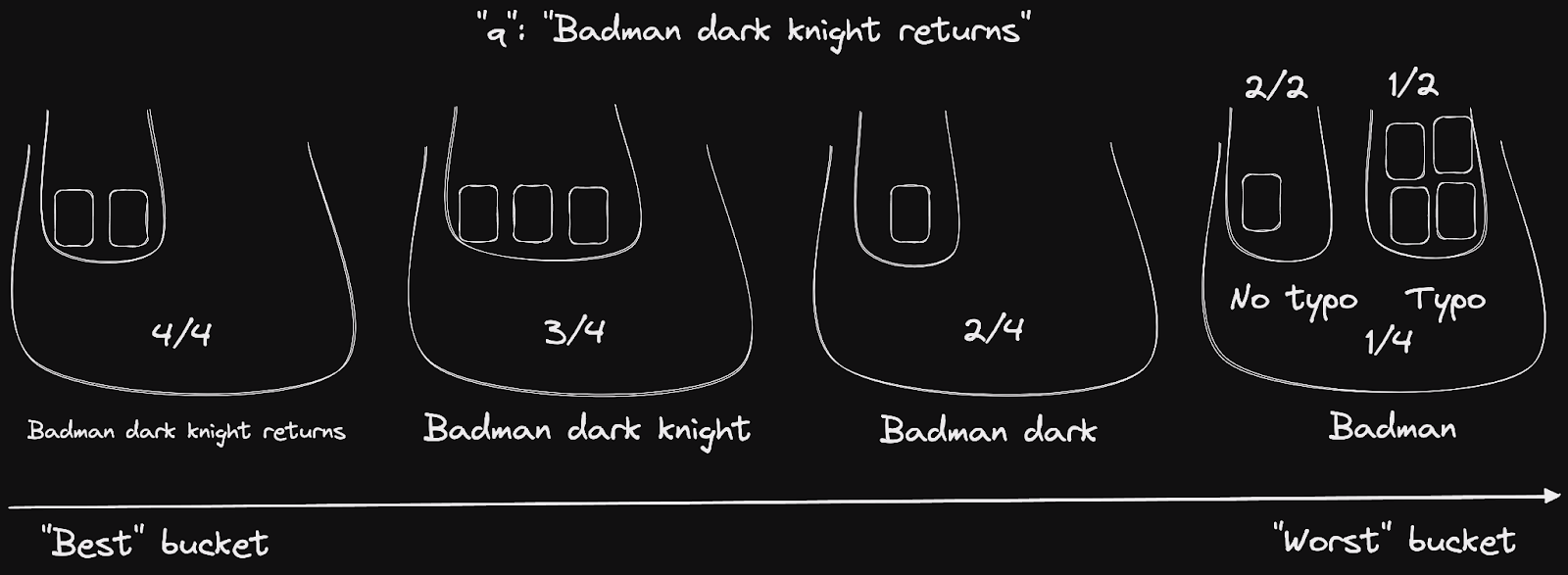
Buckets of documents, labeled by fractional scores
By applying recursive bucket sorting to our query on the sample movies.json dataset, we get the ranking below. For simplicity, we have configured the dataset so that only title is a searchable attribute, which makes the results easier to grasp. With this, we are able to assign a detailed score made of two components to each document, arriving at the following:
| Word & typo score | Movie title |
|---|---|
words 4/4,typo 1/1 | - Batman: The Dark Knight Returns, Part 1 |
| - Batman: The Dark Knight Returns, Part 2 | |
words 3/4, typo 1/1 | - Batman Unmasked: The Psychology of the Dark Knight |
| - Legends of the Dark Knight: The History of Batman | |
words 1/4, typo 2/2 | - Angel and the Badman |
words 1/4, typo 1/2 | - Batman: Year One |
| - Batman: Under the Red Hood |
This provides a first shape for our per-ranking rule, detailed scores, although we might want to augment the scores with semantic information that is rule specific, such as the number of matching words, and the number of typos.
We have yet to explore how we generate a single score per document from these detailed scores, how we ensure its independence from the dataset, and how we handle the unique case of sorting rules.
So, how do we get from these complex scores–suited for advanced use cases–to a single aggregated score per document for the use cases that don’t require such a high level of detail? We'll discuss it in the following section.
Aggregating scores
To keep the scoring system intuitive, the aggregate score must be consistent with the rankings given by Meilisearch. Let's bear in mind that subsequent ranking rules are used primarily to resolve ties from previous rules. Similarly, a later ranking rule should only refine the score derived from the prior rule.
With this in mind, let’s modify our previous diagram. Instead of labeling the words bucket with “4/4” for documents that match all the words , let’s say that documents in this bucket fall in the range from 3/4 to 4/4. We’ll let the typo ranking rule decide where they fall exactly. Taking only the last words bucket since it is the one that has two typo inner buckets:
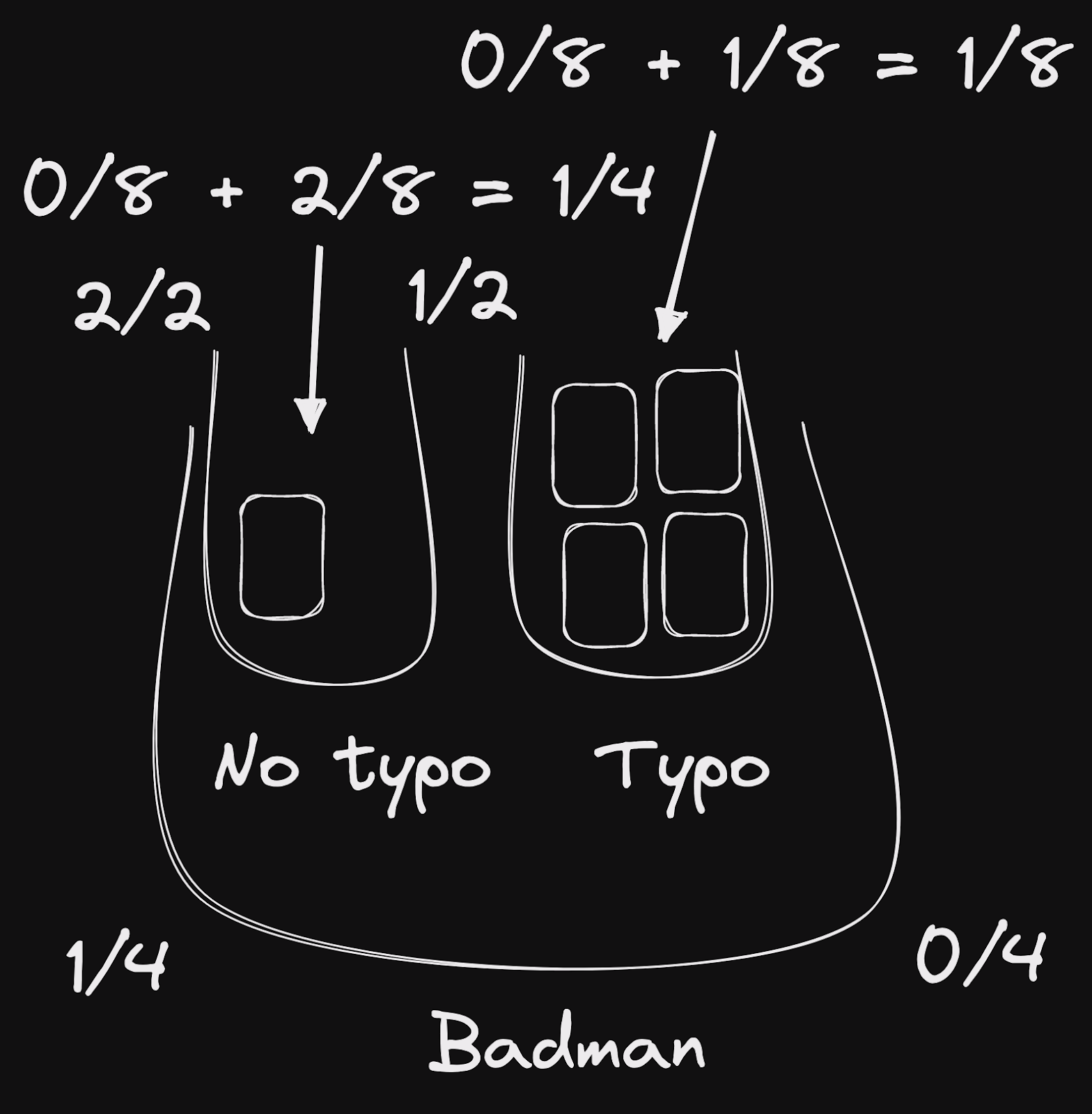
This way, we can compute the aggregate score of each document:
words4/4,typo1/1: 1.0words3/4,typo1/1: 0.75words1/4,typo2/2: 0.25words1/4,typo1/2: 0.125

The above gives an intuition of the scores, but care should be taken with the specifics of the implementation. In particular, we only put a single typo bucket for the 3 best words buckets, because in our index we had no document falling in these words buckets without a typo on “Batman”.
Now, what happens if we add a new movie titled “The badman returns to the dark knight”? We now have two typo buckets for the first words bucket, and “Batman: the dark knight returns, part 1” is no longer a perfect match: its score becomes 0.875 rather than 1.0. We need to avoid this issue.
Reaching dataset independence
Our scores should be perfectly independent from the documents contained in the index. Each rule should be able to compute the theoretical maximum number of buckets depending solely on the query, not on the documents from the index.
For the typo rule this involves applying the index typo tolerance settings to the query and computing the maximum possible number of typos. The default settings typically allow for 1 typo in terms of five or more characters, and up to 2 typos for terms that are at least nine characters long.
With these settings, the query “Badman dark knight returns” allows a maximum of 3 typos (1 on “badman”, 1 on “knight”, 1 on “returns”), totaling 4 possible buckets from 0 to 3 typos. This means that “Batman: the dark knight returns, part 1” should actually score 0.9375, regardless of whether “The badman returns to the dark knight” is a movie that exists in the index or anywhere (correcting the scores in the tier list above is left as an exercise to the reader).
Fortunately, for most ranking rules, computing that theoretical maximum number of buckets can be done in a natural way (detailing that way for each ranking rule is out of the scope of this article, but we’re taking questions if you’re interested 😊). Unfortunately, the sort and geosort ranking rules are notable exceptions.
Sorting rules do not influence the score
The family of sorting rules allow sorting documents by the values of one of their fields.
This raises an issue. If we need the maximum number of buckets a rule can return, what should that number be when sorting e.g. by a product’s price? Remember, the value must be independent of the documents in the index.
We considered multiple options here, such as inferring automatically various buckets depending on the value distribution, while still allowing developers to specify the bucketing at scoring time. Ultimately, we went with the simplest option, one that adds no additional API surface: the scores are unaffected by the sort ranking rules. They are handled as if they were returning a single bucket.
This decision generates some mismatch impedance, because, in practice, Meilisearch ranks the documents in buckets of the same value when using sort ranking rules. What this means is that, if your ranking rules sort by ascending price before differentiating by typo, you’ll get the following order:
- documents with price $100, without typos
- documents with price $100, with typos
- documents with price $200, without typos again
- documents with price $200, with typos
Since the sort ranking rule does not influence the score, the relevancy score of documents returned in (2) will be lower than those returned in (3). After all, the former have typos, and the latter don’t. This can be surprising to users and is something we would have liked to avoid, but couldn’t find a practical way of doing so.
Another way to look at the problem might make it seem more natural. While most ranking rules sort documents by relevancy, the sort-by-field ranking rules sort them by the values of that field, and ultimately, there can only be one order.
To summarize, when using the aggregate score to rank documents, the effect of any sort by field ranking rule is negated in the ranking. When using detailed scores this is not an issue because the detailed scores provide the value that was used to rank the document for sort-by-field ranking rules, so the developer can take them into account when re-ranking.
Using the scoring API
Meilisearch v1.3 allows to specify a showRankingScore query parameter in search requests, and setting that parameter to true results in a _rankingScore float value being injected into the documents returned by the search.
One can then fetch the score for each document, and e.g. choose a distinct emoji or CSS class depending on the value.
| Score | Emoji |
|---|---|
| 0.99 | 👑 |
| 0.95 | 💎 |
| 0.90 | 🏆 |
| ... | ... |
| 0.25 | 🐓 |
I’m sure developers will come up with many ways of using this score, way more imaginative than this poor backend engineer’s attempt 😳
Meilisearch v1.3 also exposes the _rankingScoreDetails. However, since they are adding a large API surface, it is currently gated behind a runtime experimental flag. Your feedback is appreciated!
Conclusion
Implementing the relevancy score is an example of the design process that takes place at Meilisearch for a complex feature with a large design space.
It also represented a nice opportunity for great community interaction, as we released several prototypes of the feature and got feedback from users. We would like to thank user @LukasKalbertodt in particular, whose great feedback on a prototype definitely helped us improve the solution ❤️
The early results we obtained with the scoring API are very promising:
- Debugging relevancy. Meilisearch v1.3 already features relevancy improvements that were made obvious by the detailed scores revealing relevancy issues
- Unlocking aggregated search. Using the aggregate scores to re-rank documents coming from heterogeneous search queries and indexes unlocks a first version of aggregated search. If using the experimental feature switch to enable the detailed scores, they can be used to re-rank documents in a finer way
- Unlocking hybrid search. Relevancy scores can be used as a means of implementing hybrid search, together with the work we’ve been doing on [semantic search](/blog/vector-search-announcement/
We hope you appreciated the deep dive into the scoring feature, and that it will be useful to you. Feel free to give us feedback on our Discord community.
For more things Meilisearch, you can also subscribe to our newsletter, check out our roadmap, participate in our product discussions, build from source or create a project on the Cloud. See you around!

Patching LMDB: how we made Meilisearch’s vector store 3× faster
We patched LMDB to support nested read transactions on uncommitted writes - eliminating full database scans and making Meilisearch's vector store 3× faster

Why traditional hybrid search falls short (and how we fixed it)
Meilisearch's innovative scoring system revolutionizes hybrid search by properly combining full-text and semantic search, delivering more relevant results than traditional rank fusion methods.

Introducing Meilisearch's next-generation indexer: 4x faster updates, 30% less storage
Indexer edition 2024 revolutionizes search performance with parallel processing, optimized RAM usage, and enhanced observability. See what's new in our latest release.